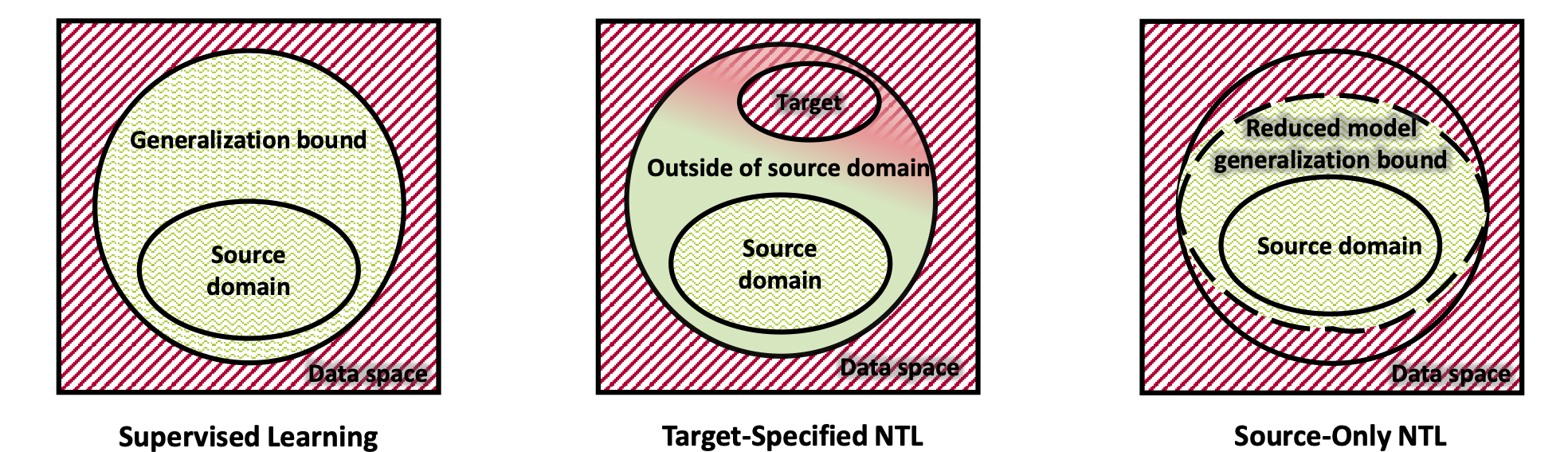
As Artificial Intelligence as a Service gains popularity, protecting well-trained models as intellectual property is becoming increasingly important. There are two common types of protection methods: ownership verification and usage authorization. In this paper, we propose Non-Transferable Learning (NTL), a novel approach that captures the exclusive data representation in the learned model and restricts the model generalization ability to certain domains. This approach provides effective solutions to both model verification and authorization. Specifically: 1) For ownership verification, watermarking techniques are commonly used but are often vulnerable to sophisticated watermark removal methods. By comparison, our NTL-based ownership verification provides robust resistance to state-of-the-art watermark removal methods, as shown in extensive experiments with 6 removal approaches over the digits, CIFAR10 & STL10, and VisDA datasets. 2) For usage authorization, prior solutions focus on authorizing specific users to access the model, but authorized users can still apply the model to any data without restriction. Our NTL-based authorization approach instead provides a data-centric protection, which we call applicability authorization, by significantly degrading the performance of the model on unauthorized data. Its effectiveness is also shown through experiments on aforementioned datasets.
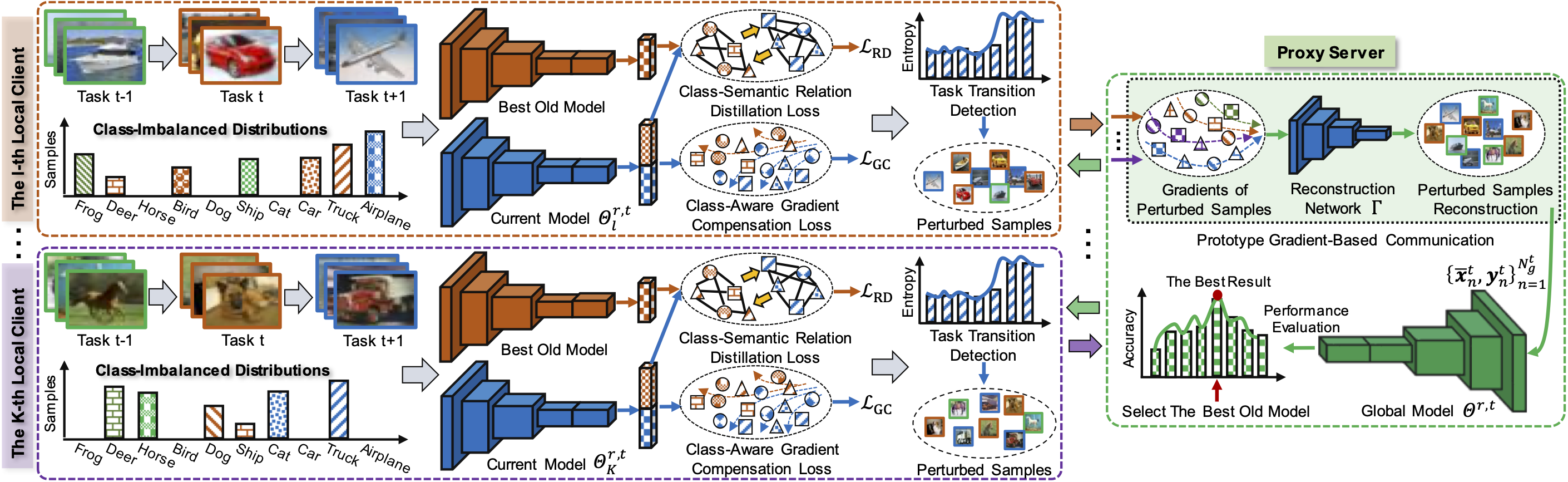
Federated learning (FL) has attracted growing attentions via data-private collaborative training on decentralized clients. However, most existing methods unrealistically assume object classes of the overall framework are fixed over time. It makes the global model suffer from significant catastrophic forgetting on old classes in real-world scenarios, where local clients often collect new classes continuously and have very limited storage memory to store old classes. Moreover, new clients with unseen new classes may participate in the FL training, further aggravating the catastrophic forgetting of global model. To address these challenges, we develop a novel Global-Local Forgetting Compensation (GLFC) model, to learn a global class-incremental model for alleviating the catastrophic forgetting from both local and global perspectives. Specifically, to address local forgetting caused by class imbalance at the local clients, we design a class-aware gradient compensation loss and a class-semantic relation distillation loss to balance the forgetting of old classes and distill consistent inter-class relations across tasks. To tackle the global forgetting brought by the non-i.i.d class imbalance across clients, we propose a proxy server that selects the best old global model to assist the local relation distillation. Moreover, a prototype gradient-based communication mechanism is developed to protect the privacy. Our model outperforms state-of-the-art methods by 4.4%~15.1% in terms of average accuracy on representative benchmark datasets.
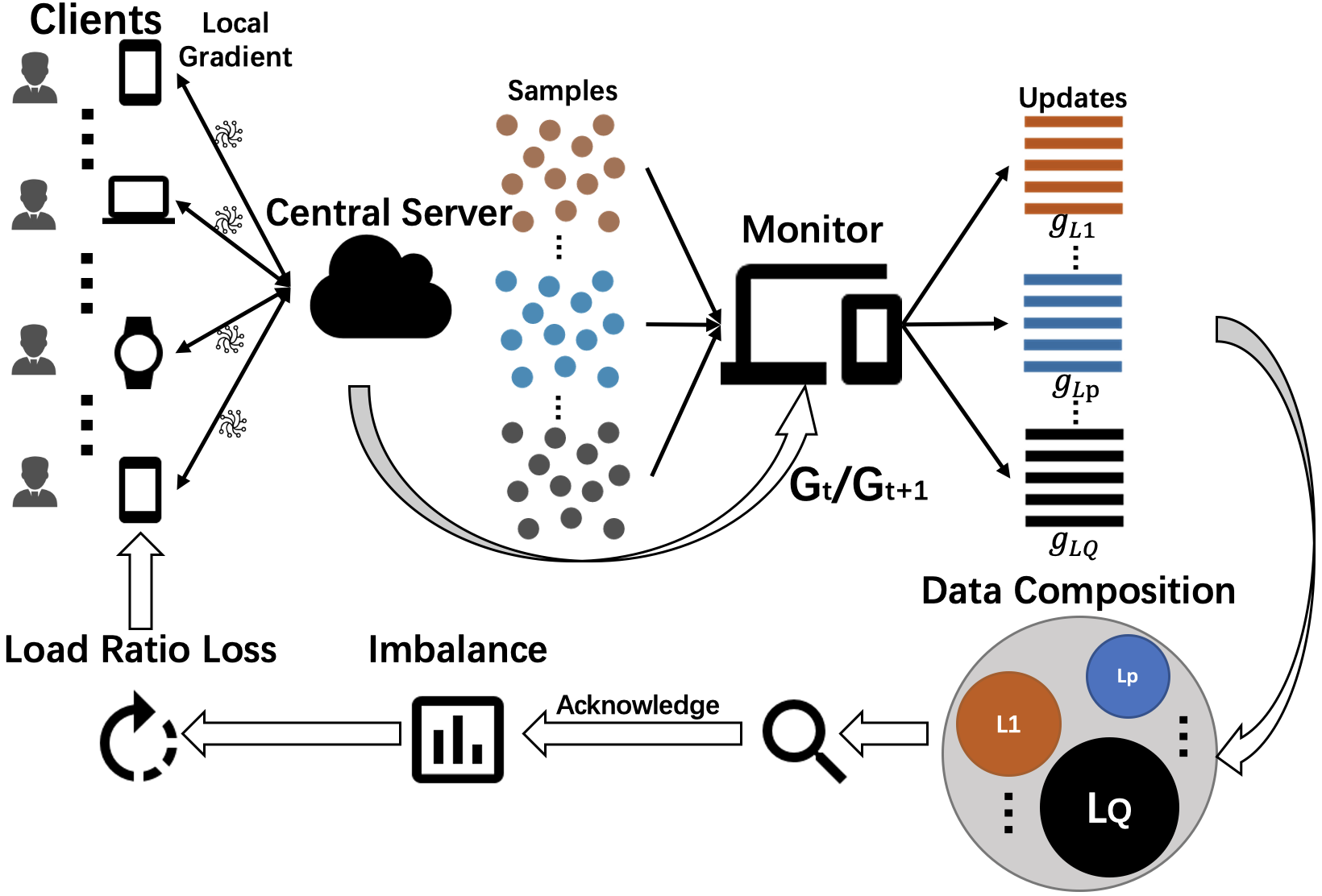
Federated learning (FL) is a promising approach for training decentralized data located on local client devices while improving efficiency and privacy. However, the distribution and quantity of the training data on the clients' side may lead to significant challenges such as class imbalance and non-IID (non-independent and identically distributed) data, which could greatly impact the performance of the common model. While much effort has been devoted to helping FL models converge when encountering non-IID data, the imbalance issue has not been sufficiently addressed. In particular, as FL training is executed by exchanging gradients in an encrypted form, the training data is not completely observable to either clients or servers, and previous methods for class imbalance do not perform well for FL. Therefore, it is crucial to design new methods for detecting class imbalance in FL and mitigating its impact. In this work, we propose a monitoring scheme that can infer the composition of training data for each FL round, and design a new loss function -- Ratio Loss to mitigate the impact of the imbalance. Our experiments demonstrate the importance of acknowledging class imbalance and taking measures as early as possible in FL training, and the effectiveness of our method in mitigating the impact. Our method is shown to significantly outperform previous methods, while maintaining client privacy.